There is a metric everyone in the AI space is obsessing over right now: Velocity.
“I built this app in 20 minutes.”
“I generated this marketing strategy in 30 seconds.”
“I automated this workflow in an afternoon.”
Speed is intoxicating. We look at a demo and think, “Wow, look how much time we saved.” But as an Ops Architect with years in the industry, I look at this speed and I don’t just see “Efficiency.” I see a new, dangerous form of liability. I call it “Prompt Debt.”
What is Prompt Debt?
In traditional software, we have “Technical Debt” the cost of choosing an easy solution now instead of a better approach that would take longer. Prompt Debt is the AI equivalent.
But let me be clear: I’m not talking about playground prompts or ChatGPT conversations. I’m talking about the prompts hardcoded into your production applications—the system prompts powering your customer service bot, the extraction logic in your document processor, the routing rules in your email automation. These prompts are buried in your codebase, controlling business logic. And most teams are treating them like throwaway comments instead of critical infrastructure.
Here’s what it looks like:
You’re building an automated invoice processing system. Your developer writes this:

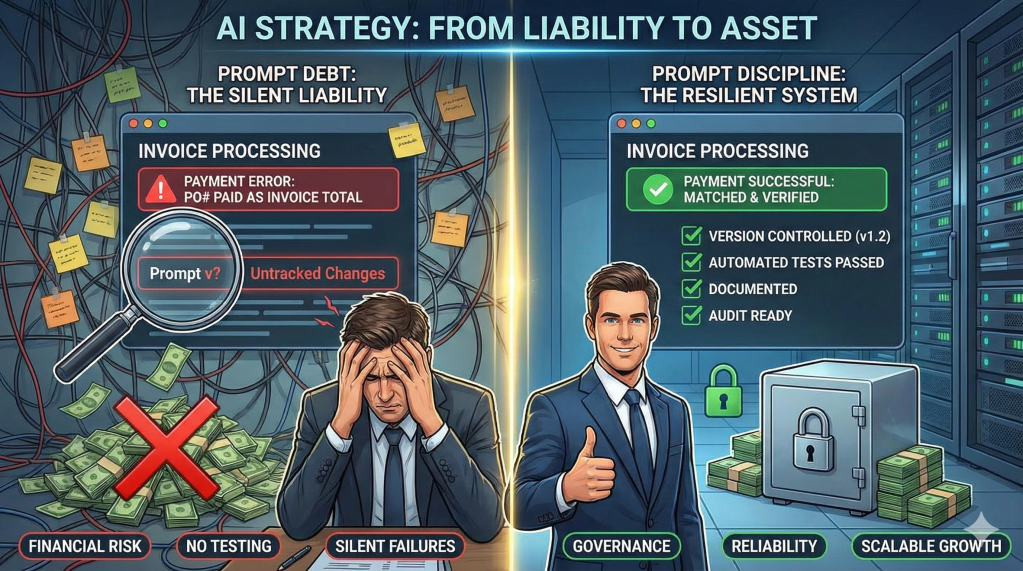
It works perfectly in testing. It ships to production. Next week, a vendor sends an invoice with a slightly different format. The AI extracts the PO number as the invoice number. Your accounts payable just paid the wrong invoice.
Here’s the real problem: Unlike code, which throws a syntax error when it breaks, Prompt Debt fails silently. It just gives you the wrong answer with 100% confidence. We are building legacy code at the speed of light.
The 5 Symptoms of Prompt Debt
If you are leading an engineering or ops team deploying AI, audit your codebase for these warning signs:
1. The “Magic String” Liability
Imagine this scenario: You have a production system where the entire customer escalation logic lived in a 400-word system prompt written by an intern who’d since left the company.
Nobody on the current team knows why specific phrases were included. When needed they will be afraid to refactor it because they didn’t understand the logic holding it together.
The test: If your business process depends on a “Magic String” that only one person understood, you don’t have maintainable code. You have a dependency that just walked out the door.
2. The Copy-Paste Spiral
Engineer A writes a great extraction prompt for invoice processing. Engineer B needs something similar for purchase orders, so they copy it and tweak two lines.
Now you have two prompts that are 80% identical living in different parts of your codebase. Six months later, you discover the vendor name extraction has a bug.
Do you fix both? How do you even know both exist? How many other copies are there?
The debt: You’ve created unmaintainable duplication, just in natural language instead of functions.
3. The Version Control Black Hole
Your document classifier has been working fine for 3 months. Someone thinks it needs to handle more edge cases, so they update the prompt string.
Seems harmless. But now your downstream validation logic which was built expecting 4 categories starts breaking because a new category was added.
You want to roll back the prompt change. But in your Git history, it’s buried in a commit with 47 other changes titled “bug fixes and improvements.”
The reality: Prompt changes ARE code changes, but they’re not being tracked or reviewed with the same rigor.
4. The “Model Drift” Tax
Your production system has a prompt carefully tuned over weeks for GPT-5. It works beautifully. Then OpenAI releases GPT-5.2. Your infrastructure auto-updates to the latest model (because you didn’t pin the version).
Suddenly, the outputs change format. Your parser which was built expecting the old format starts failing. When you build business logic into prompts, you couple your operation to the quirks of one model version. When that model updates, your debt comes due immediately.
5. The Testing Gap
Your codebase has unit tests for everything except the prompt logic. When you “improve” a prompt, you manually test it on 3 examples, it looks better, and you deploy to 100% of traffic.
Three weeks later you notice processing accuracy dropped 15%. The new prompt is more conversational but less precise.
The problem: No regression tests. No performance benchmarks. No A/B testing. You’re flying blind on the most critical business logic.
Why This Matters Now
2023: Prompts were experiments in Jupyter notebooks. Failure was cheap.
2026: Prompts are production infrastructure. Customer service runs on them. Financial processes depend on them. Compliance audits need to review them.
The stakes have changed, but our practices haven’t. Here’s what’s coming:
Auditor: “Your AI denied this insurance claim. Show me the decision logic.”
You: “Uh… it’s in this system prompt… I think someone updated it last month… or was it the staging branch version?”
This doesn’t pass audit. And when that prompt controlled a decision that cost someone money, “the AI did it” isn’t a legal defense.
How to Pay Down the Debt
The “Builder Era” was about who could generate the most output. The “Editor Era” is about who can build the most resilient systems.
1. Extract Prompts to Versioned Configuration
Move critical prompts out of your code into versioned config files with documentation:
- What the prompt does
- Why specific phrasings exist
- What changed in each version
- Who to consult before editing
Now your prompts can be reviewed independently and rolled back without redeploying code.
2. Build Prompt Test Suites
For every critical prompt, create 10-20 test cases covering happy paths AND edge cases. Before deploying any prompt change:
- Run it against your test suite
- Compare performance metrics: old vs. new
- A/B test on 10% of traffic first
- Only promote if measurably better
Your standard: “No prompt change goes to production without passing its test suite.”
3. Treat Prompt Changes Like Code Changes
Require the same rigor as function changes:
- Dedicated pull requests (not buried in large commits)
- Explanation of WHY the change is needed
- Test results showing improvement
- Review from someone who understands the business logic
4. Define Explicit Failure States
Stop optimizing only for the “Happy Path.”
Bad Prompt: “Extract the data”
Debt-Free Prompt: “Extract the data. If confidence < 0.8 for any field, return ERROR_MANUAL_REVIEW and stop processing”
When things go wrong, they should fail explicitly and safely instead of silently propagating bad data.
5. Pin Your Model Versions
If your prompt is tuned for a specific model, make it explicit in your code. When you DO upgrade models, treat it like a dependency upgrade: test thoroughly, update in staging first, monitor metrics closely, have rollback ready.
Start Small: The 4-Week Action Plan
- Week 1: Audit Search your codebase for hardcoded prompts. List which ones control business logic. Identify your top 5 “critical” prompts.
- Week 2: Extract & Version Move those 5 prompts into versioned config files. Add context documentation. Tag current version as “v1.0.”
- Week 3: Build Test Suite For each critical prompt, create 10-20 test cases. Run baseline: document current accuracy/performance.
- Week 4: Establish Process Write a one-page “Prompt Change Policy”: All changes require tests and code review. Practice it on the next prompt update.
That’s 80% of the value with 20% of the effort.
The Reality Check
It is easy to get caught up in the hype of building with LLMs. The speed is addictive. The demos are impressive. But “built in 20 minutes” doesn’t mean “maintainable for 20 months.”
We spent years learning to treat code with discipline: version control, code reviews, testing frameworks, documentation standards. Then LLMs arrived, and suddenly business logic written in natural language doesn’t get the same rigor.
The uncomfortable truth: The moment your prompt controls production behavior, it IS code. It deserves the same engineering discipline.
Right now, this is manageable. Most production systems have 10-50 prompts embedded in their codebase. But in 12-24 months:
- You’ll have 200+ prompts across your microservices
- Foundation models will update more frequently
- Regulatory bodies will demand explainability
- The technical debt compounds
The teams that will succeed: Started treating prompts as first-class code artifacts early, before the crisis.
The teams that will struggle: Waited until they had hundreds of prompts in chaos and tried to retrofit governance after a production incident.
Don’t let the velocity hype trick you into accumulating debt at the speed of light.
It is better to ship a “boring” system with proper prompt engineering discipline that survives 5 years, than a “demo magic” system that breaks in 5 weeks.
The future belongs to teams with the best systems, not the fastest demos.
Build for maintenance. Build for scale. Build for the long term.
Your future self & your on-call engineer at 2am will thank you.
Found this useful? I’ll be breaking down more practical strategies for operationalizing AI in future editions of The Abhay Perspective. Subscribe below & also to my Newsletter on LinkedIn to get more such updates


Leave a comment